I’ve always been fascinated with Natural Language Processing and finally have a few tools under my belt to tackle this in a meaningful way. There is an old competition on Kaggle for sentiment analysis on movie reviews. The link to the competition can be found here.
As per the Kaggle website – the dataset consists of tab-separated files with phrases from Rotten Tomatoes. Each sentence has been parsed into many phrases by the Stanford parser. Our job is to learn on the test data and make a submission on the test data. This is what the data looks like.
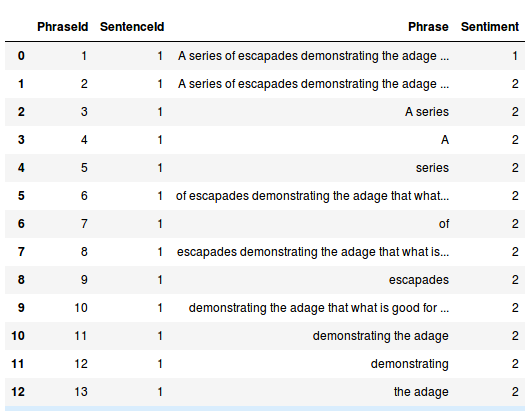
Each review (Sentiment in the above image) can take on values of 0 (negative), 1 (somewhat negative), 2 (neutral), 3 (somewhat positive) and 4 (positive). Our task is to predict the review based on the review text.
I decided to try a few techniques. This post will cover using a vanilla Neural Network but there is some work with the preprocessing of the data that actually gives decent results. In a future post I will explore more complex tools like LSTMs and GRUs.
Preprocessing the data is key here. As a first step we tokenized each sentence into words and vectorized the word using word embeddings. I used the Stanford GLOVE vectors. I assume word2vec would give similar results but GLOVE is supposedly superior since it captures more information of the relationships between words. Initially I ran my tests using the 50 dimensional vectors which gave about 60% accuracy on the test set and 57.7% on Kaggle. Each word then becomes a 50-dimensional vector.
For a sentence, we take the average of the word vectors as inputs to our Neural Network. This approach has 2 issues
- Some words don’t exist in the Glove database. We are ignoring them for now, but it may be useful to find some way to address this issue.
- Averaging the word embeddings means we fail to capture the position of the word in the sentence. That can have an impact on some reviews. For example if we had the following review
Great plot, would have been entertaining if not for the horrible acting and directing.
This would be a bad review but by averaging the word vectors we may be losing this information.
For the neural network I used 2 hidden layers with 1024 and 512 neurons. The final output goes through a softmax layer and we use the standard cross-entropy loss since this is a classification problem.
Overall the results are quite good. Using 100 dimensional GLOVE vectors, we get 62% accuracy on the test set and 60.8% on the Kaggle website.
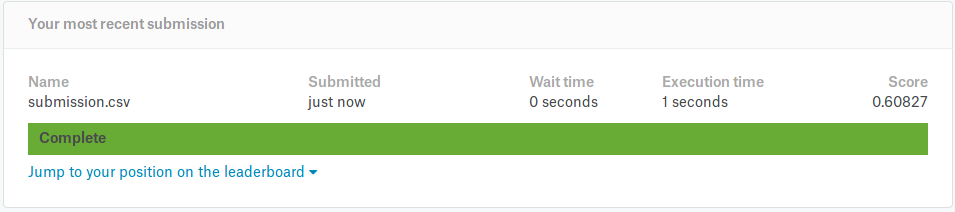
Pre-trained vectors seem to be a good starting point to tackling NLP problems like this. The hyperparameter weight matrices will automatically tweak them for the task at hand.
Next steps are to explore larger embedding vectors and deeper neural networks to see if the accuracy improves further. Also play with regularization, dropout, and try different activation functions.
The next post will explore using more sophisticated techniques like LSTMs and GRUs.
Source code below (assuming you get the data from Kaggle)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
import numpy as np import pandas as pd import numpy as np import csv #from nltk.tokenize import sent_tokenize,word_tokenize from nltk.tokenize import RegexpTokenizer from sklearn.preprocessing import LabelBinarizer from sklearn.model_selection import train_test_split glove_file='../glove/glove.6B.100d.txt' pretrained_vectors=pd.read_table(glove_file, sep=" ", index_col=0, header=None, quoting=csv.QUOTE_NONE) base_vector=pretrained_vectors.loc['this'].as_matrix() def vec(w): try: location=pretrained_vectors.loc[w] return location.as_matrix() except KeyError: return None def get_average_vector(review): numwords=0.0001 average=np.zeros(base_vector.shape) tokenizer = RegexpTokenizer(r'\w+') for word in tokenizer.tokenize(review): #sentences=sent_tokenize(review) #for sentence in sentences: # for word in word_tokenize(sentence): value=vec(word.lower()) if value is not None: average+=value numwords+=1 #else: # print("cant find "+word) average/=numwords return average.tolist() class SentimentDataObject(object): def __init__(self,test_ratio=0.1): self.df_train_input=pd.read_csv('/home/rohitapte/Documents/movie_sentiment/data/train.tsv',sep='\t') self.df_test_input=pd.read_csv('/home/rohitapte/Documents/movie_sentiment/data/test.tsv',sep='\t') self.df_train_input['Vectorized_review']=self.df_train_input['Phrase'].apply(lambda x:get_average_vector(x)) self.df_test_input['Vectorized_review'] = self.df_test_input['Phrase'].apply(lambda x: get_average_vector(x)) self.train_data=np.array(self.df_train_input['Vectorized_review'].tolist()) self.test_data=np.array(self.df_test_input['Vectorized_review'].tolist()) train_labels=self.df_train_input['Sentiment'].tolist() unique_labels=list(set(train_labels)) self.lb=LabelBinarizer() self.lb.fit(unique_labels) self.y_data=self.lb.transform(train_labels) self.X_train,self.X_cv,self.y_train,self.y_cv=train_test_split(self.train_data,self.y_data,test_size=test_ratio) def generate_one_epoch_for_neural(self,batch_size=100): num_batches=int(self.X_train.shape[0])//batch_size if batch_size*num_batches<self.X_train.shape[0]: num_batches+=1 perm=np.arange(self.X_train.shape[0]) np.random.shuffle(perm) self.X_train=self.X_train[perm] self.y_train=self.y_train[perm] for j in range(num_batches): batch_X=self.X_train[j*batch_size:(j+1)*batch_size] batch_y=self.y_train[j*batch_size:(j+1)*batch_size] yield batch_X,batch_y |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
import tensorflow as tf import SentimentData #import numpy as np import pandas as pd sentimentData=SentimentData.SentimentDataObject() INPUT_VECTOR_SIZE=sentimentData.X_train.shape[1] HIDDEN_LAYER1_SIZE=1024 HIDDEN_LAYER2_SIZE=1024 OUTPUT_SIZE=sentimentData.y_train.shape[1] LEARNING_RATE=0.001 NUM_EPOCHS=100 BATCH_SIZE=10000 def truncated_normal_var(name, shape, dtype): return (tf.get_variable(name=name, shape=shape, dtype=dtype, initializer=tf.truncated_normal_initializer(stddev=0.05))) def zero_var(name, shape, dtype): return (tf.get_variable(name=name, shape=shape, dtype=dtype, initializer=tf.constant_initializer(0.0))) X=tf.placeholder(tf.float32,shape=[None,INPUT_VECTOR_SIZE],name='X') labels=tf.placeholder(tf.float32,shape=[None,OUTPUT_SIZE],name='labels') with tf.variable_scope('hidden_layer1') as scope: hidden_weight1=truncated_normal_var(name='hidden_weight1',shape=[INPUT_VECTOR_SIZE,HIDDEN_LAYER1_SIZE],dtype=tf.float32) hidden_bias1=zero_var(name='hidden_bias1',shape=[HIDDEN_LAYER1_SIZE],dtype=tf.float32) hidden_layer1=tf.nn.relu(tf.matmul(X,hidden_weight1)+hidden_bias1) with tf.variable_scope('hidden_layer2') as scope: hidden_weight2=truncated_normal_var(name='hidden_weight2',shape=[HIDDEN_LAYER1_SIZE,HIDDEN_LAYER2_SIZE],dtype=tf.float32) hidden_bias2=zero_var(name='hidden_bias2',shape=[HIDDEN_LAYER2_SIZE],dtype=tf.float32) hidden_layer2=tf.nn.relu(tf.matmul(hidden_layer1,hidden_weight2)+hidden_bias2) with tf.variable_scope('full_layer') as scope: full_weight1=truncated_normal_var(name='full_weight1',shape=[HIDDEN_LAYER2_SIZE,OUTPUT_SIZE],dtype=tf.float32) full_bias2 = zero_var(name='full_bias2', shape=[OUTPUT_SIZE], dtype=tf.float32) final_output=tf.matmul(hidden_layer2,full_weight1)+full_bias2 logits=tf.identity(final_output,name="logits") cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits,labels=labels)) train_step=tf.train.AdamOptimizer(learning_rate=LEARNING_RATE).minimize(cost) correct_prediction=tf.equal(tf.argmax(final_output,1),tf.argmax(labels,1),name='correct_prediction') accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32),name='accuracy') init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) test_data_feed = { X: sentimentData.X_cv, labels: sentimentData.y_cv, } for epoch in range(NUM_EPOCHS): for batch_X, batch_y in sentimentData.generate_one_epoch_for_neural(BATCH_SIZE): train_data_feed = { X: batch_X, labels: batch_y, } sess.run(train_step, feed_dict={X:batch_X,labels:batch_y,}) validation_accuracy=sess.run([accuracy], test_data_feed) print('validation_accuracy => '+str(validation_accuracy)) validation_accuracy=sess.run([accuracy], test_data_feed) print('Final validation_accuracy => ' +str(validation_accuracy)) #generate the submission file num_batches=int(sentimentData.test_data.shape[0])//BATCH_SIZE if BATCH_SIZE*num_batches<sentimentData.test_data.shape[0]: num_batches+=1 output=[] for j in range(num_batches): batch_X=sentimentData.test_data[j*BATCH_SIZE:(j + 1)*BATCH_SIZE] test_output=sess.run(tf.argmax(final_output,1),feed_dict={X:batch_X}) output.extend(test_output.tolist()) #print(len(output)) sentimentData.df_test_input['Classification']=pd.Series(output) #print(sentimentData.df_test_input.head()) #sentimentData.df_test_input['Sentiment']=sentimentData.df_test_input['Classification'].apply(lambda x:sentimentData.lb.inverse_transform(x)) sentimentData.df_test_input['Sentiment']=sentimentData.df_test_input['Classification'].apply(lambda x:x) #print(sentimentData.df_test_input.head()) submission=sentimentData.df_test_input[['PhraseId','Sentiment']] submission.to_csv('submission.csv',index=False) |