There was an FT article recently (25th March 2019) on Banks using AI to catch rogue traders before the act. The second paragraph stood out for me –

How would one go about tackling something like this? We would use something called Stylometry. Stylometry is often used to attribute authorship to anonymous or disputed documents. In this post we will try and apply Stylometry to emails to see if we can identify the writer.
Due to privacy issues, its not easy to get a dataset of email conversations. The one that I managed to find was the Enron Email Dataset which contains over 500,000 emails generated by employees of Enron. It was obtained by the Federal Energy Regulatory Commission during its investigation of Enron’s collapse.
The Enron dataset contains emails in MIME format. This is what a sample email looks like
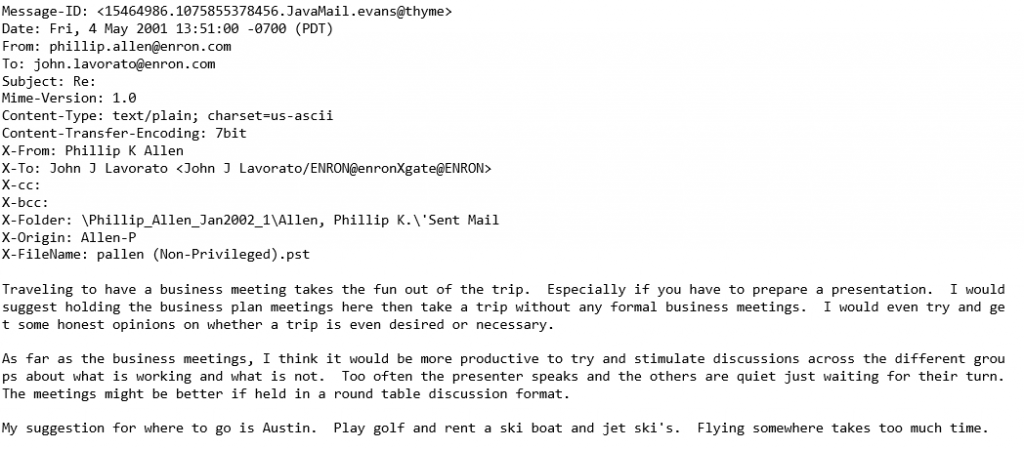
I took the emails and stripped them of any forwarded or replied to text, and disclaimers to preserve only what the person actually wrote. This is important since we are analyzing writing style. I also added the option to filter by messages of a minimum length (more on that later). Lastly I restricted the analysis to the 10 most active people in the dataset.
| kay.mann@enron.com | vince.kaminski@enron.com |
| jeff.dasovich@enron.com | chris.germany@enron.com |
| sara.shackleton@enron.com | tana.jones@enron.com |
| eric.bass@enron.com | matthew.lenhart@enron.com |
| kate.symes@enron.com | sally.beck@enron.com |
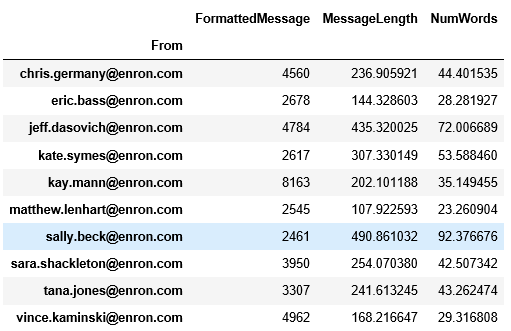
We get just over 40,000 emails with a decent distribution across all the people. An analysis of the average length and number of words for each person already shows us that each person is quite different in how they write emails.
For our analysis we will split the data into training and test sets, apply Stylometric analysis to the training data and use it to predict the test data.
For Stylometric analysis I used John Burrow’s delta method. Published in 2002, it is a widely used and accepted method to analyze authorship. Here are the steps for calculating the delta
- Take the entire corpus (our training set) and find the n most frequent words.
- Calculate the probability of each of these words occurring in the entire corpus (freq distribution of the word/total words in the corpus).
- Calculate the mean and standard deviation of the occurrence of the word for each author.
- Calculate the z-scores for every word for every author.
- For the text in the test set, calculate the probabilities of the frequent words and their z-scores.
- The delta = Sum of absolute value of difference in z scores divided by n.
- The smallest delta is the one we predict to be the author.
What do the results look like? Overall, pretty good considering we are trying to classify emails as belonging one of 10 possible authors with very little data (usually one identifies the author for a book, and has a large corpus to generate word frequencies). For example, it automatically picks up the fact that someone tends to use quotes a lot
Author: jeff.dasovich@enron.com
Email: I’d like to do everything but the decking for the deck. We can hold off on that.
In addition, I may have some “salvaged” redwood decking I may want to add to the mix once I get ready to install the decking.
Best, Jeff
Scores: {‘kay.mann@enron.com’: 7.43433684056309, ‘vince.kaminski@enron.com’: 7.337718602815618, ‘jeff.dasovich@enron.com’: 7.056721256733514, ‘chris.germany@enron.com’: 7.522215636238818, ‘sara.shackleton@enron.com’: 7.5393982224001945, ‘tana.jones@enron.com’: 7.434437992786343, ‘eric.bass@enron.com’: 7.54634308986968, ‘matthew.lenhart@enron.com’: 7.517654790021831, ‘kate.symes@enron.com’: 7.624201059391151, ‘sally.beck@enron.com’: 7.548497152341907}
Author: kay.mann@enron.com
Email: I have a couple of questions so I can wrap up the LOI:
We refer to licensed Fuel Cell Energy equipment. Do we intend to reference a particular manufacturer, or should this be more generic?
Do we want to attach a draft of the Development Agreement, and condition the final deal on agreeing to terms substantially the same as what’s in the draft? I have a concern that the Enron optionality bug could bite us on the backside with that one.
Do we expect to have ONE EPC contract, or several?
I’m looking for the confidentiality agreement, which may be in Bart’s files (haven’t checked closely yet). If anyone has it handy, it could speed things up for me.
Thanks, Kay
{‘kay.mann@enron.com’: 6.154191709401956, ‘vince.kaminski@enron.com’: 6.397433577625913, ‘jeff.dasovich@enron.com’: 6.396576407146207, ‘chris.germany@enron.com’: 6.642765292897169, ‘sara.shackleton@enron.com’: 6.56876557432365, ‘tana.jones@enron.com’: 6.249601335542451, ‘eric.bass@enron.com’: 6.595756852792294, ‘matthew.lenhart@enron.com’: 6.7300358896137595, ‘kate.symes@enron.com’: 6.4104713094426815, ‘sally.beck@enron.com’: 6.318539264208084}
The predictions tend to do better on longer emails. On smaller emails as well as emails that don’t betray a writing style it doesn’t do a very good job. For example
Author: chris.germany@enron.com
Email: Please set up the following Service Type, Rate Sched combinations.
Pipe Code EGHP
Firmness Firm
Service Type Storage
Rate Sched FSS
Term Term
thanks
Scores: {‘kay.mann@enron.com’: 8.032067481552536, ‘vince.kaminski@enron.com’: 7.686060503779472, ‘jeff.dasovich@enron.com’: 7.76376151369006, ‘chris.germany@enron.com’: 8.088435461708675, ‘sara.shackleton@enron.com’: 7.837802283010304, ‘tana.jones@enron.com’: 8.356182289848462, ‘eric.bass@enron.com’: 8.285958154167018, ‘matthew.lenhart@enron.com’: 8.502751475726505, ‘kate.symes@enron.com’: 8.061320580331817, ‘sally.beck@enron.com’: 8.535085342764473}
How does filtering for longer emails affect our accuracy? How do we measure accuracy across the entire test set? I stole a page from the Neural Network playbook.
- Take the negative of our delta score (negative because lower is better).
- Apply SoftMax to convert it to probabilities.
- Calculate the cross entropy log loss.
Overall we do see an improvement filtering for larger emails but not by a much. This is partly because Burrow’s delta is quite stable and works on smaller datasets, as well as due to nuances in the Enron data.
| Minimum words | Cross Entropy Log Loss |
| 0 | 18.40066081813624 |
| 10 | 18.356774963612363 |
| 20 | 18.309804439201955 |
| 30 | 18.30380323248317 |
| 40 | 18.282598926893684 |
| 50 | 18.291281635444992 |
| 60 | 18.292350501846915 |
| 70 | 18.299773312100324 |
| 80 | 18.29375907006795 |
| 90 | 18.26679623872471 |
How can we adapt this to what the FT described? Given enough training data (emails from a trader) we can establish a baseline style (use of words, sentence length, etc.) and check for variations from that baseline. More than 2 standard deviations from that baseline could warrant a more closer look. If we have historical data of when rogue behavior occurred, we could use that to train our features to determine which one are better predictors for this change in behavior.
Source code for this project can be found on my GitHub. You will need to download the Enron email data file (link on my git) for the code to work.